
Supervised
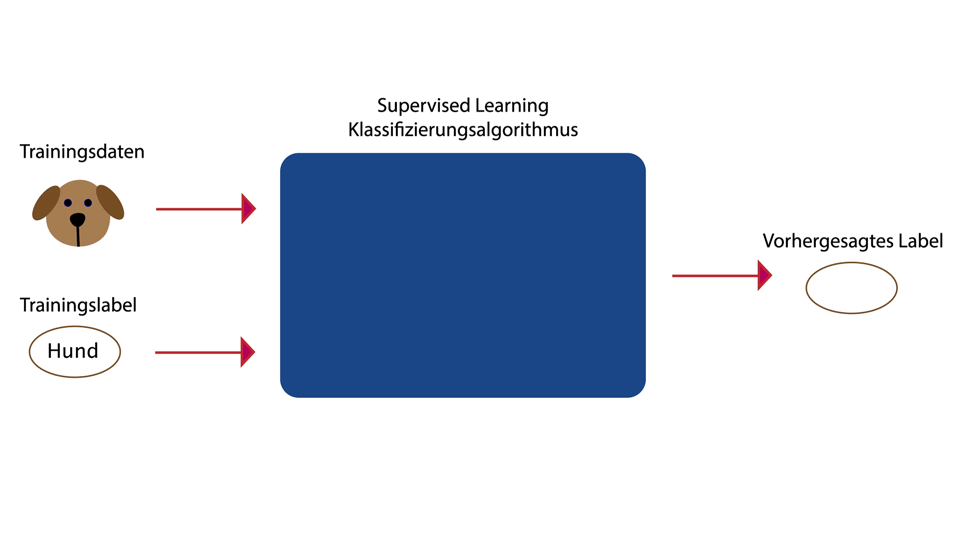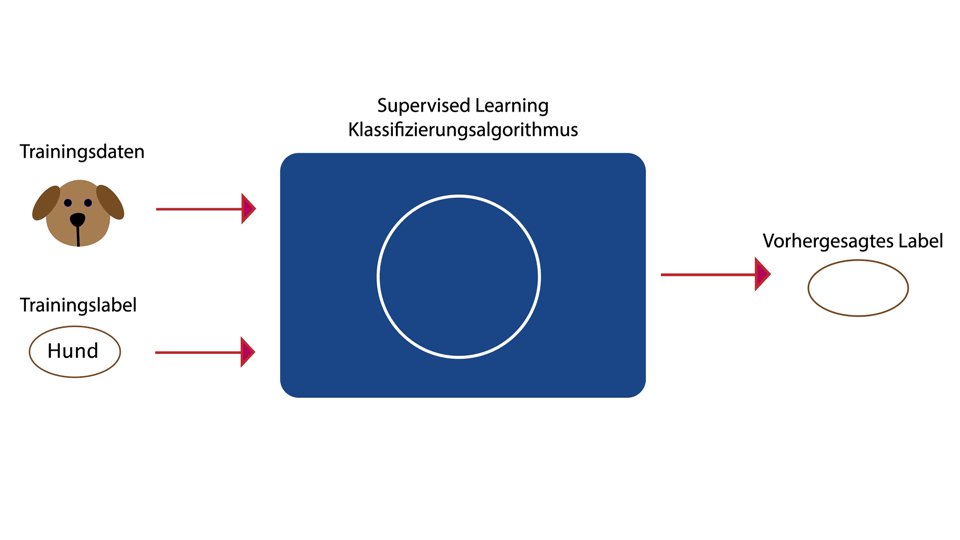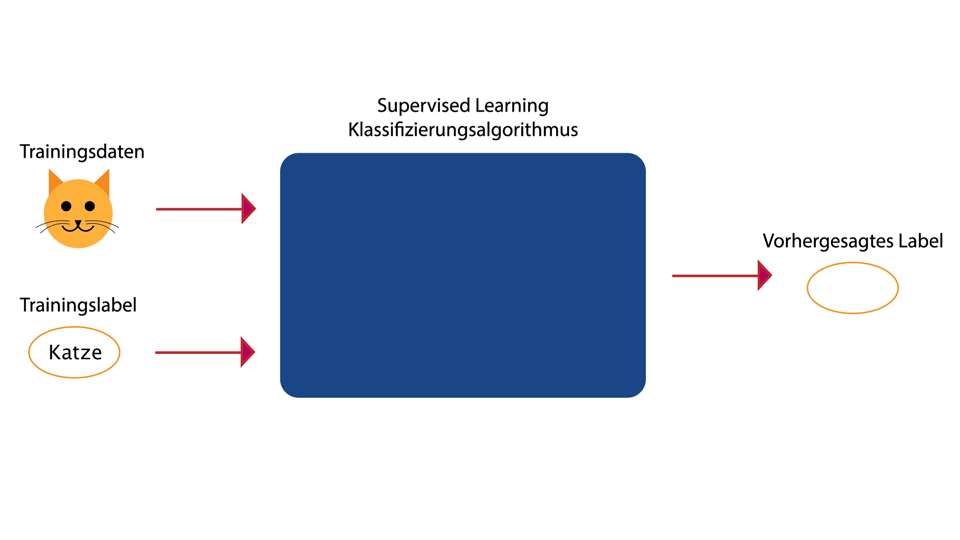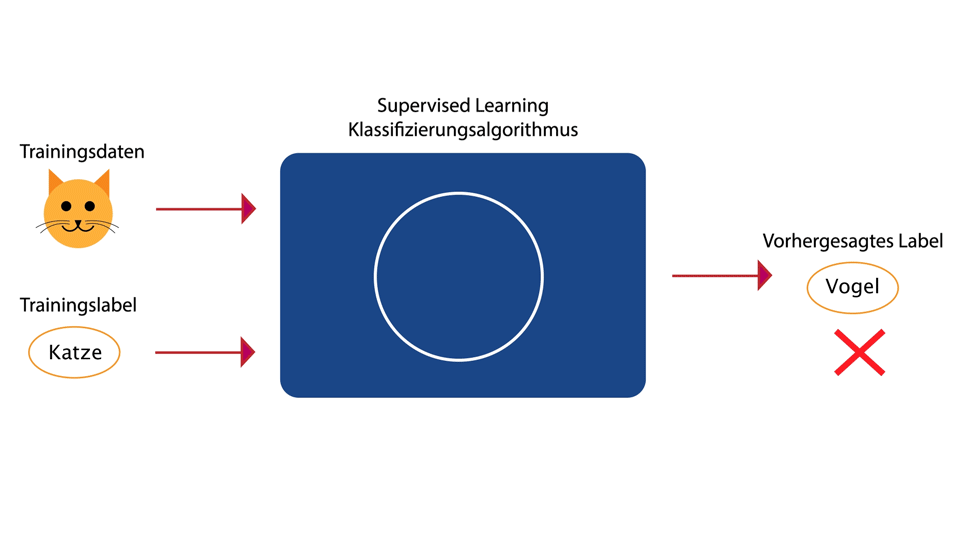
Lernen mit Zieldaten (Label / Target)
- Target fuer jeden Datensatz
- Training durch vergleich Output = Target
- Klassifizierung, Spracherkennung
Unsupervised
Lernen ohne Zieldaten
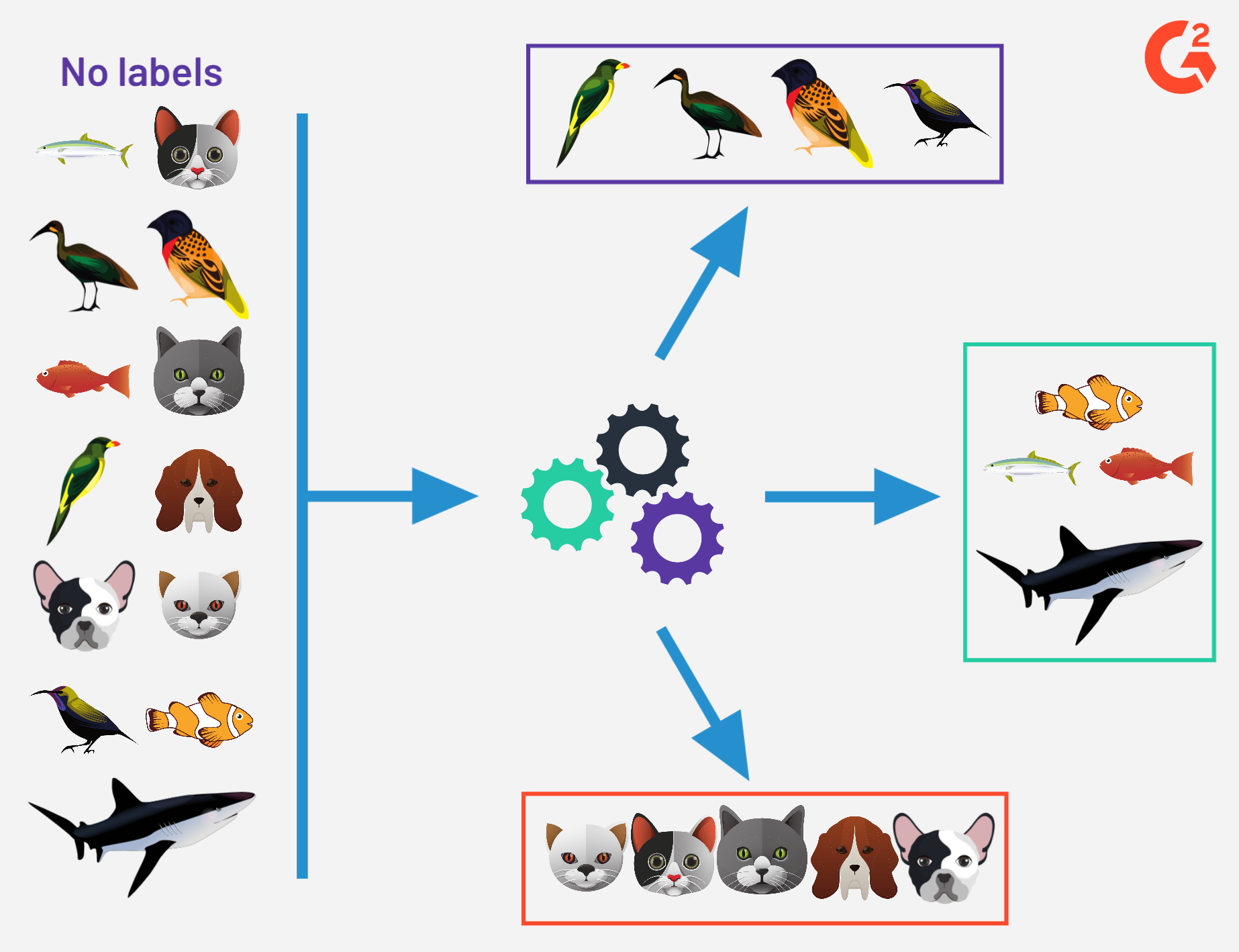
- Kein Target pro Datensatz
- Muster & Strukturen erkennen
- Clustering, Dimensionsreduktion
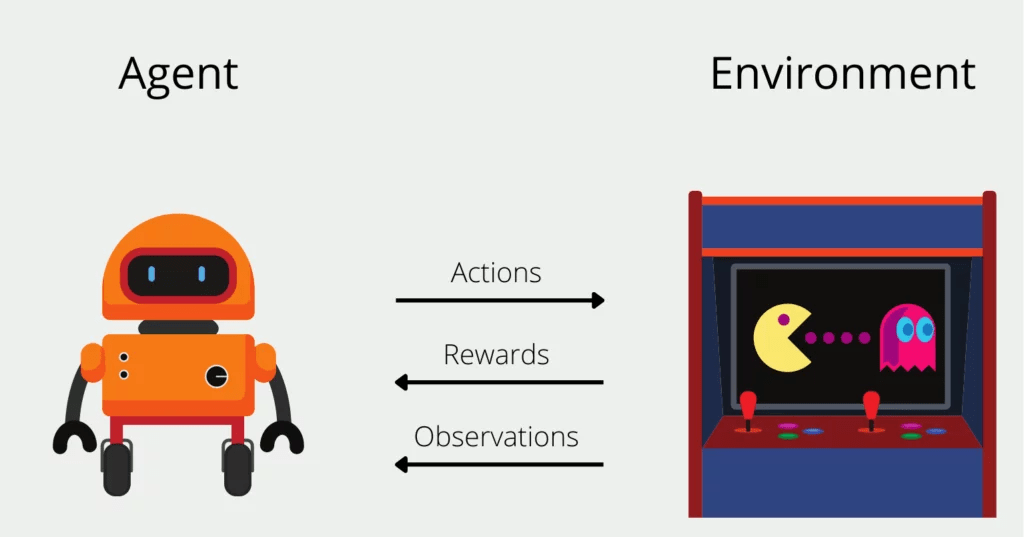
Reinforcement
Interaktion mit Umgebung
- Lernen durch Interaktion
- Belohnung & Bestrafung
- Spiele, Roboter, Autonome Systeme
Daten Erkunden
- Verstehen: Inhalt, Format, Label, Metadaten
- Visualisieren: Verteilung, Korrelation, Ausreisser
- Preprocessing: normalisieren, skalieren, enkodieren, balancieren
Daten Erkunden
Hands-On: MNIST Datensatz
Welche Daten enthält der Datensatz?
data.shape -> (N_data, size_input)Die shape eines Datensatzes zeigt die Anzahl der Elemente (N_data) sowie das format der einzelnen Elemente (size_input)
Daten Erkunden
Hands-On: MNIST Datensatz
Welches Format haben die Daten?
Die type(x) Funktion gibt die Klasse von x an
type(data[0]) -> classDie built-in Funktion x.dtype gibt den Datentyp von x an
data.dtype -> data_typeDaten Erkunden
Hands-On: MNIST Datensatz
Welche Klassen gibt es und wie sind diese verteilt?
numpy.unique(x) liefert eine liste aller Elemente die in x vorkommen
labels = np.unique(target)numpy.bincount(x) liefert die Anzahl von Integerwerten in x, geordnet nach Zahlenwert der Integer
counts = np.bincount(target.astype(int))Daten Erkunden
Hands-On: MNIST Datensatz
Wie machen wir die Klassen dem Modell verständlich?
Um Stringlabel in für das Modell verständliche Floats zu verwandeln nutzen wir One-Hot-Encoding
# zB "3" -> [0,0,0,1,0,0,0,0,0,0]
#
from sklearn.preprocessing import OneHotEncoder
encoder = OneHotEncoder()
labels = encoder.fit_transform(target)Achtung: Die letzte Zeile erwartet hier target mit shape (N,1)
Daten Erkunden
Hands-On: MNIST Datensatz
Welche Skalierung der Daten ist sinnvoll?
- Knoten: Summe vieler Werte -> sehr grosse Werte
- Features: grösseres Wertinterval ~ stärkeres Gewicht.
- => Input-Daten auf [-1,1] skaliert.
- idR mit Min-Max scaling
scaled_data = (data - np.min(data)) / (np.max(data) - np.min(data)) * 2 - 1
Daten Erkunden
Hands-On: MNIST Datensatz
Öffnen sie dieses Notebook und bearbeiten Sie die Aufgaben. Beantworten Sie so folgende Fragen:
- Welche Daten enthält der Datensatz?
- Welches Format haben die Daten?
- Welche Klassen gibt es und wie sind diese verteilt?
- Wie machen wir die Klassen dem Modell verständlich?
- Welche Skalierung der Daten ist sinnvoll?
Die Lösung finden Sie in diesem Notebook