Optimieren
Optimieren
Optimieren

Modell auf unbekannten Daten optimieren
aber
Testset erst ganz zum Schluss verwenden
Train-Test-Valid Split
Modell auf unbekannten Daten optimieren
aber
Testset erst ganz zum Schluss verwenden
Weiteres Datenset absplitten
Train-Test-Valid Split
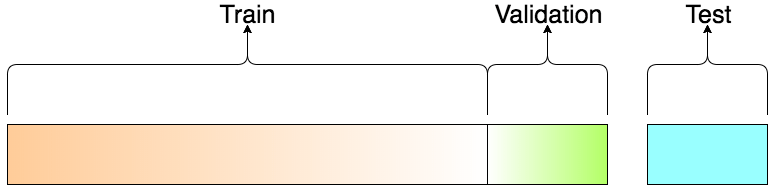

Train-Test-Valid Split
Machine Learning 60% 20% 20%
Deep Learning 98% 1% 1%
Gross genug für stabile Statistik
Train-Test-Valid Split
- verschiedene Settings wählen (Hyperparameter / Architektur)
- für wenige Epochen trainieren
- Leistung auf Validationsdaten vergleichen
- Setting mit bester Leistung voll trainieren
- Trainiertes Modell auf Testset Evaluieren
Train-Test-Valid Split
- verschiedene Settings wählen (Hyperparameter / Architektur)
- für wenige Epochen trainieren
- Leistung auf Validationsdaten vergleichen
- Setting mit bester Leistung voll trainieren
- Trainiertes Modell auf Testset Evaluieren
from torch.utils.data import random_split
train_ratio, valid_ratio = 0.8, 0.2
# Gesamteanzahl der Trainingsdaten
N_training = len(training_data)
# Berechne die Anzahl der Beispiele für jeden Split
train_size = int(train_ratio * N_training)
valid_size = N_training - train_size
# Teile den Trainingsdatensatz in Train und Valid auf
train_data, valid_data = random_split(training_data,
[train_size, valid_size])
Train-Test-Valid Split
- verschiedene Settings wählen (Hyperparameter / Architektur)
- für wenige Epochen trainieren
- Leistung auf Validationsdaten vergleichen
- Setting mit bester Leistung voll trainieren
- Trainiertes Modell auf Testset Evaluieren
from torch.utils.data import random_split
train_ratio, valid_ratio = 0.8, 0.2
# Gesamteanzahl der Trainingsdaten
N_training = len(training_data)
# Berechne die Anzahl der Beispiele für jeden Split
train_size = int(train_ratio * N_training)
valid_size = N_training - train_size
# Teile den Trainingsdatensatz in Train und Valid auf
train_data, valid_data = random_split(training_data,
[train_size, valid_size])
import tensorflow as tf
from sklearn.model_selection import train_test_split
valid_ratio = 0.2
input_data = your_input_data
labels = your_labels
input_train, input_valid, labels_train, labels_valid =
train_test_split(input_data, labels, test_size=valid_ratio, random_state=42)
# Create TensorFlow Datasets
train_dataset = tf.data.Dataset.from_tensor_slices((input_train, labels_train))
valid_dataset = tf.data.Dataset.from_tensor_slices((input_valid, labels_valid))
Hyperparameter
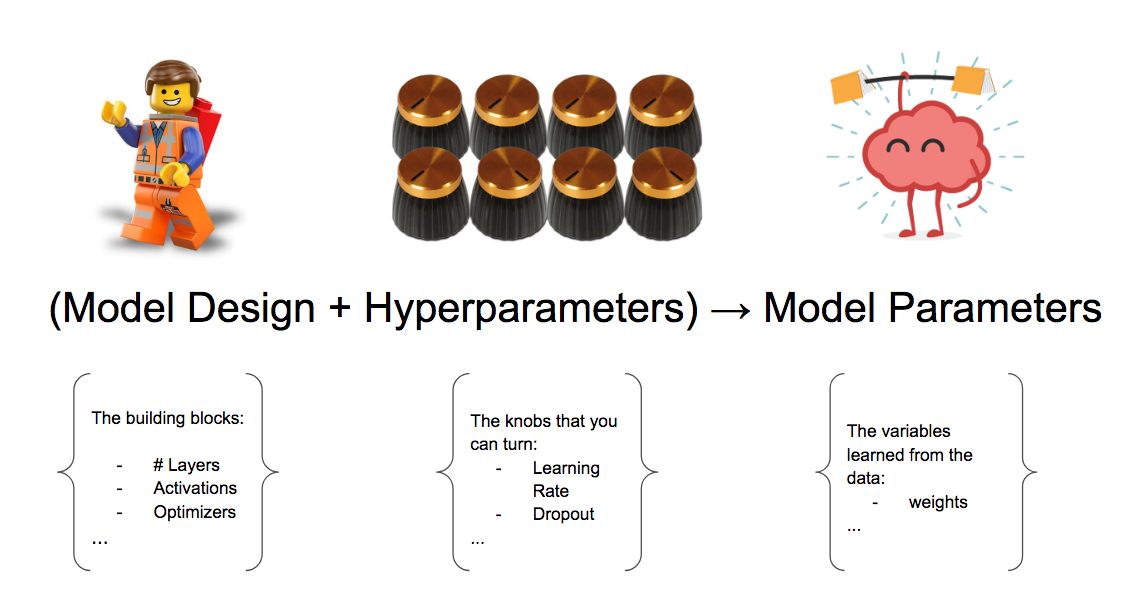
Hyperparameter
class MLP_var(nn.Module):
def __init__(self, N_layer: int):
super(MLP_var, self).__init__()
layers = []
layers.append(nn.Linear(28*28, 64))
layers.append(nn.ReLU())
for _ in range(N_layer-1):
layers.append(nn.Linear(64, 64))
layers.append(nn.ReLU())
layers.append(nn.Linear(64, 10))
self.model = nn.Sequential(*layers)
def forward(self, x):
x = x.view(x.size(0), -1)
x = self.model(x)
return x
Hyperparameter Search

Hyperparameter Search
Try different Values, pick best score
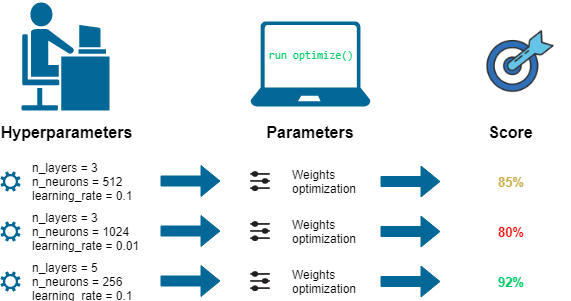
Hyperparameter Search
Try different Values, pick best score
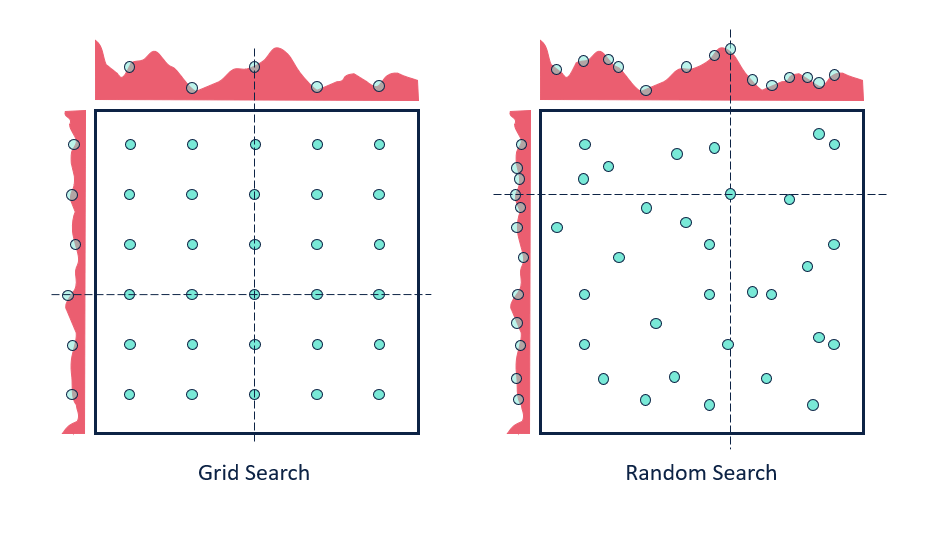
Hyperparameter Search
Gridsearch
for (N_layer, lr) in product(N_layer_values, learning_rate_values):
model = MLP_var(N_layer)
model.to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=lr)
losses_train, losses_valid, f1_scores_train, f1_scores_valid = full_training(
model, criterion, optimizer, training_loader, valid_loader, epochs=epochs
)Einfluss auf Stabilität
N_{\text{Params}}
N_{\text{Data}}
Regularisierung
Hyperparameter
Tuning
Optimizer
Aufwand
N_{\text{Params}}
Hyperparameter
Tuning
Optimizer
N_{\text{Data}}
Regularisierung
Optimieren
Hands-On: MNIST Classifier
Bearbeiten Sie dieses Notebook
- Erstellen Sie einen MNIST Classifier
mit variabler Anzahl hidden Layer
- Erstellen Sie einen Validationsdatensatz
- Führen sie ein Hyperparametertuning durch
Die Lösung finden Sie in diesem Notebook